To delve deeper into Teradata architecture, it’s essential first to understand the fundamental structure of a computer, as this forms the foundation of a Teradata system.
Teradata Architecture – Why Does Everyone Copy It?
Teradata has been a pioneer in data warehousing and an exemplary model for subsequent database systems regarding architecture.
Teradata has stood the test of time thanks to its developers’ foresight, who initially incorporated many details into the system. These details have enabled Teradata to remain competitive to this day.
Examining contemporary database systems, such as Amazon’s Redshift (or Netezza), reveals several features initially implemented by Teradata.
Teradata was originally created with a focus on parallelism in even the most minute aspects, placing it among the leading relational database management systems (RDBMS) for data warehousing to this day.
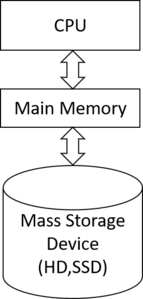
Data is stored on mass storage devices and loaded into the CPU’s memory for processing.
It is crucial to comprehend that accessing the mass storage device is significantly slower than accessing the main memory. Additionally, accessing data already in one of the CPU caches is much faster than accessing the main memory.
Before processing data, the CPU requires it to be loaded into the primary memory.
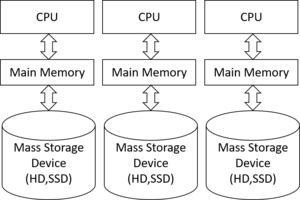
The Teradata architecture consists of multiple interconnected computers.
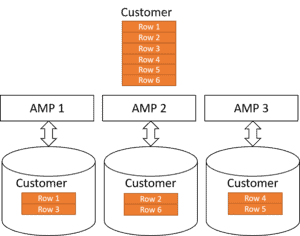
Teradata Data Distribution
Teradata employs a hashing algorithm to evenly distribute table rows among AMPs responsible for executing the primary tasks. (Further details on AMPs will be discussed later in this article.)
The Parsing Engine
The Parsing Engine (PE) is a crucial component of the Teradata architecture.
The Parsing engine generates an execution plan for all necessary AMPs upon receiving a request (such as an SQL statement) to complete the said request. Ideally, the plan is structured to allow simultaneous task starting and finishing among all the AMPs. This guarantees the best possible utilization of the system in parallel.
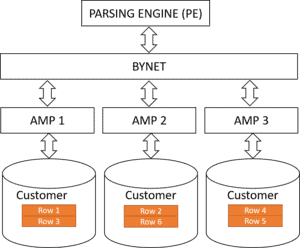
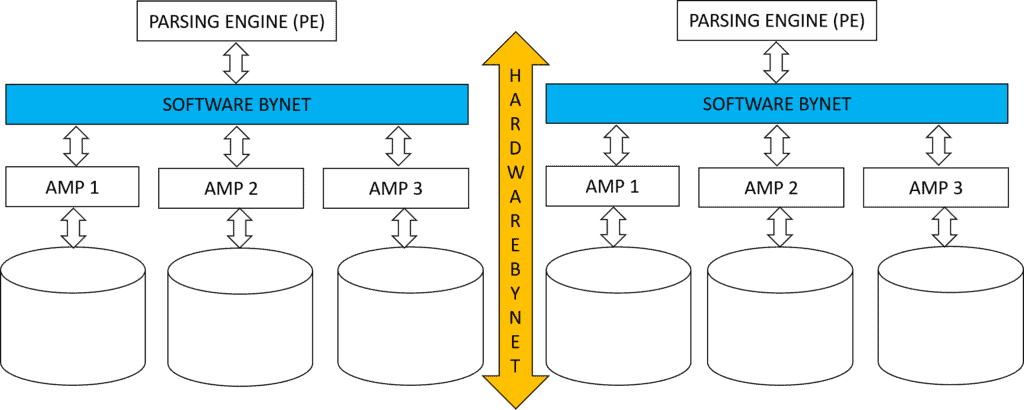
The figure above illustrates the position of the BYNET between the AMPs and the parsing engine, which facilitates the exchange of data and instructions via a communication network. Further explanation on BYNET will be provided later in this article.
The main responsibilities of the Parsing Engine include:
- Logging on and Logging Off Sessions
- The parsing of requests (syntax check, checking authorizations)
- Preparation and optimization of the execution plan
- The Parsing Engines use statistics to build an optimized plan.
- Controlling the AMPs by Instructions
- Communication with the client software
- EBCDIC to ASCII conversion in both directions
- Transfers of the result of a request to the client tool
Teradata Systems have the capability to utilize multiple parsing engines.
The system can augment the required parsing engines as each has a finite capability to handle sessions.
A parsing engine currently manages up to 120 sessions, which may consist of multiple users or up to 120 sessions for a single user.
The Teradata AMP
AMPs are the primary agents in a Teradata System that execute instructions from the Parsing Engine, also known as the Execution Plan.
AMPs are autonomous entities with dedicated primary memory and storage resources.
Each AMP has exclusive access to its allocated resources.
The primary responsibilities of an AMP include:
- Storing and retrieving rows
- Sorting of rows (for details, read How Teradata sorts the result set)
- Aggregation of rows
- Joining of tables (see also: The Essential Teradata Join Methods)
- Locking of tables and rows
- Output conversion ASCII to EBCDIC (if the client is a mainframe)
- Management of its assigned space
- Sending of rows to the Parsing Engine or other AMPs (via the BYNET)
- Accounting
- Recovery handling
- Filesystem management
Each AMP can concurrently perform multiple tasks. Teradata has a default capacity to execute 80 parallel tasks.
The Teradata Node
Parsing engines and AMPs run on a node, typically a Linux machine with multiple physical CPUs.
Nodes have the capability to operate numerous AMPs, each with its own allocation of primary and virtual memory.
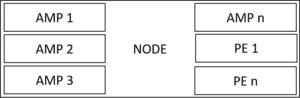
The nodes link to a disk array, and each AMP obtains a portion as a logical disk. The Teradata Intelligent Memory system controls this process, utilizing SSDs. Despite this, the fundamental concept remains unchanged.
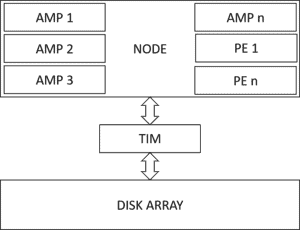
Massive Parallel Processing
A Teradata system comprises numerous nodes interconnected by BYNET.
The network within a node, known as BYNET, connects the AMPs to the parsing engine and to each other through software, in contrast to the physical network.

It is important to understand that accessing the main memory is many times slower than accessing the main memory. typo here
Thank you very much. I fixed it.
Thanks, I fixed it.
Great article, just thought you’d like to know there’s a couple of errors: “It is important to understand that accessing the main memory is many times slower than accessing the main memory.”, think that first ‘main memory’ should be ‘mass storage’.
Also the phrase “Each node can run hundreds of AMPs. Each AMP has its own portion of the main memory and its own portion of mass memory (called virtual disk).” is repeated both before and after the Teradata Node diagram.
These are minor things, thanks for writing these interesting articles. Keep up the good work.
@Jason
Thank you very much. I fixed it.