The History of Parallel Database Architectures
Parallel computing has existed for over three decades, and parallel database architectures followed shortly thereafter.
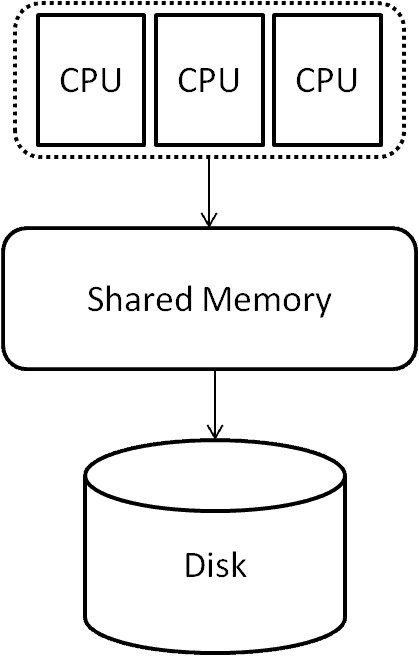
It all began with the shared memory architecture, which remains widely used in servers today.
.
The shared memory architecture is a multiprocessor system with communal memory, a solitary operating system, and a shared disk or storage area network designated for data storage. The processes are dispersed across the CPUs.
The shared memory architecture lacks scalability, which limits the number of processors in a setup to a few hundred, even with modern multi-core processors.
Current databases use two architectures: shared disk and shared-nothing (Teradata is based on the latter).
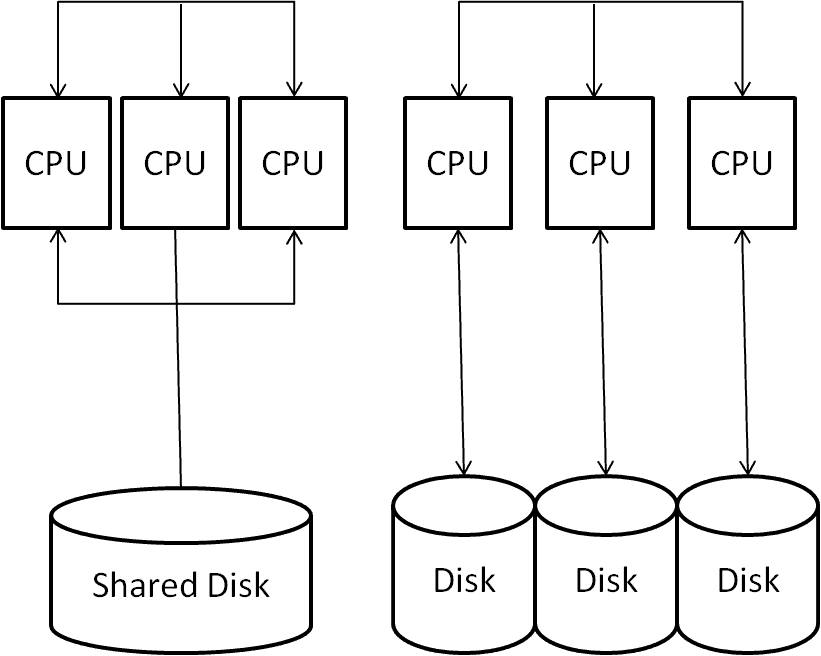
Both designs resolve the issue of limited scalability.
Shared disk architecture involves network-based communication among processors, storing data solely on a shared disk or a storage area network. This type of architecture comprises two distinct networks – one for inter-processor communication and another for communication with the disk storage system.
The shared-nothing design employs individual local disks for every processor, with processor communication exclusively reliant on the network.
Databases employing this architecture execute parallel queries, with data distributed across disks in a shared-nothing configuration.
Teradata experts can quickly identify the association between the shared-nothing configuration and the AMPs, storage units, and processor communication network known as BYNET.
A crucial objective of a database system with a shared-nothing architecture is to ensure equitable data distribution among the available disks. Teradata accomplishes this by hashing the primary index columns and storing the rows on the corresponding AMPs.
A database that utilizes a column-store approach distributes distinct columns across multiple disks. The objective remains consistent, which is to ensure equitable distribution of data to maximize parallelism efficiency.
Parallel databases and fault tolerance
Parallel databases are currently cutting-edge technology. However, fault tolerance remains a significant challenge for parallel databases, regardless of the underlying architecture.
Architectures perform well with a limited number of processors, as the likelihood of processor failure is minimal in such scenarios.
The probability of processor failure would be almost certain in a system with thousands of processors.
Parallel databases using one of the three described architectures are inherently non-fault-tolerant. To address this issue, Teradata, for instance, provides Hot Standby Nodes dedicated to replicating data across a network. Although costly, this is a commonly employed method, not exclusive to Teradata.
When comparing parallel databases to the Map-Reduce Framework (see related article for details), the parallel file system (HDFS) and fault handling stand out as a strong foundation for ensuring fault tolerance.
Batch operations are better suited for Map Reduce than parallel database systems like Teradata.
It is evident that major database vendors are now entering the realm of big data due to their unique architectural requirements.
The prevailing trend is to use “Hadoop over SQL” for a seamless transition, given that SQL is the predominant interaction language for most database systems.
We will await the future with curiosity. Teradata’s proposal is SQL-H, while other database providers work on their own integrations. However, none of them have yet persuaded me.
