The Teradata NUSI is an alternative access path to table rows, similar to other relational database indexes. Indexes are used to minimize resource consumption, especially IOs. Unlike Oracle, Teradata employs a hashing method for indexing, which is a common method for shared-nothing database systems. Amazon Redshift and Postgres-based database systems also utilize hashing.
Teradata has two types of secondary indexes: the Unique Secondary Index (USI) and the Non-Unique Secondary Index (NUSI). Although they may seem similar, these indexes have distinct implementations. This article will focus on the Teradata NUSI and clarify its differences from the USI, enabling you to determine which index to use.
The primary distinction among the Teradata NUSI, USI, and other indexes (UPI, NUPI, etc.) lies in the AMPs’ assignment of a table’s rows. Like the USI, the NUSI is stored as a distinct sub-table from the base table. However, the USI rows are distributed based on the hash value calculated over its columns. In contrast, the NUSI rows always reside on the same AMP as the corresponding base table rows. This foremost distinction significantly impacts the use of the NUSI.
It should be noted that the NUSI information is not available in the data dictionary for users. However, one can retrieve information from the DBC database for the join index.
The design of the NUSI reveals that the Teradata Optimizer cannot determine the AMP location of a NUSI Row through hashing. Thus, NUSI access is typically an all-AMP operation, which can challenge tactical queries. However, there is one exception where NUSI access can be attained through a single AMP operation: when the NUSI columns align with the table’s primary index. In such cases, NUSI can prove useful in tactical queries. Placing a NUSI above the primary index of a row partitioned table eliminates the need for partition probing, resulting in performance advantages for larger tables with numerous partitions, especially when not all partition columns are part of the primary index.
Normally the USI is a 2 AMP access (in exceptional cases also Single-AMP), and the NUSI is All-AMP access.
The NUSI offers multiple benefits for the optimizer. The Index Row contains the index columns and all ROWIDs for the associated base table rows. Thus, the optimizer can retrieve any missing data from the base table in cases where the index is not covering. The process involves creating a local spool on the AMP with relevant index rows and subsequently using the ROWIDs to access the corresponding base table rows.
Hash ordering versus value ordering
Rows in a Teradata NUSI sub-table can be ordered by ROWHASH or any 4-byte INTEGER value, depending on their intended use.
A value-ordered NUSI on the DATE column is suitable for efficiently retrieving a range of dates. Teradata stores date as 4-byte INTEGER values so that DATES can be utilized. The value-ordered NUSI was the sole method of efficiently accessing ranges of dates before joining indexes and partitioning were accessible.
Assuming we utilize an equality condition in our SQL’s WHERE clause and have defined a NUSI on these specified columns, a hash-ordered NUSI (which is the default approach) is optimal. The NUSI sub-table can be scanned via a binary search to locate the desired rows efficiently.
Teradata can employ value order exclusively on a single 4-byte integer column due to constraints imposed by the data block layout and row storage within it.
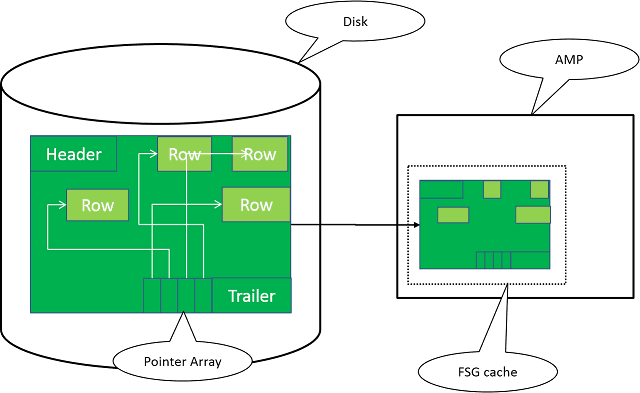
The data block only includes an orderly array of pointers to the beginning of each row, with the actual row data being inserted wherever space permits. The rows themselves are not sorted, as this would necessitate ongoing defragmentation efforts.
For row hash order, every entry in the row pointer array holds the sorted hash values, including the uniqueness value, for each corresponding row. If the index follows value ordering, every pointer array entry has the sorted INTEGER values utilized for the ordering process.
The pointer array is designed to contain either a 4-byte row hash or any other 4-byte integer value. This design limitation is necessary to maintain a fixed block structure since allowing arbitrary length values in the array would make it impossible. For instance, if we could use a column of characters with a length of 2000 for value orders, each entry in the pointer array would require 2000 bytes of space.
We can use any data type stored internally as an integer of 4 bytes for value ordering, including INTEGER, DATE, and DECIMAL (n, 0), where n occupies a maximum of 4 bytes.
Accurate statistics are crucial. The row qualification condition for NUSI columns must be highly selective for the Optimizer to use them. Without collected statistics, the Optimizer will resort to sample statistics, but the cost advantage of NUSI usage is estimated more conservatively. However, table skewing can result in the inappropriate use of NUSI, which may increase data access costs.
Requirements for a Teradata NUSI to be considered by the Optimizer
According to Teradata documentation, an existing NUSI may not be utilized if over 10% of table rows meet the criteria. However, this is merely a guideline. In my experience, NUSIs have been utilized with up to 35% qualifying rows and avoided by the optimizer even when less than 1% of table rows meet the criteria.
Additional methods exist for improving index usage estimations.
The Optimizer employs NUSI solely when it accesses the qualifying rows in the index sub-table, as reading the base table’s data blocks containing the qualifying rows in tandem is less costly than performing a full table scan on said table. Extra deliberation is necessary if multiple NUSI indexes merge or NUSI bit mapping is employed.
The Optimizer approximates the number of base table blocks retrieved, disregarding any index usage. The approximation is based on the estimated number of qualifying rows for the index value in question and the row length and data block size. The qualifying rows are determined by gathered or sampled statistics.
Assuming an average data block size of 1,000 bytes and an average row length of 100 bytes, each data block can accommodate approximately ten rows.
The optimizer will only consider NUSI access efficient if fewer than 10% of the rows qualify. If more than 1 out of 10 rows need to be selected, Teradata will perform a full table scan. This is due to the fact that, on average, selecting more than 1 row out of 10 results in reading approximately one row per data block, equivalent to a full table scan.
If less than 10% of the rows qualify, the Optimizer will disregard the NUSI. Although not all base table data blocks will have qualifying rows, they must still be read in the event of a full table scan.
Rows in the base table are stored in row hash order, allowing for binary searching of data blocks. Conducting a full table scan directly on the base table necessitates sequential checking of all block rows.
Let’s examine some practical examples to identify when the Optimizer would consider a NUSI, assuming the requisite statistics are accessible and selectivity is high:
| Example | Index on columns | Equality WHERE condition | Index Usage |
| 1 | {A, B} | A | Never used |
| 2 | {A,B} | A, B | Used if strong selectivity is given |
| 3 | {A,B} | A,B,C | Used if strong selectivity is given |
| 4 | Two separate NUSI, AND combined: {A},{B} | A = ‘value1’ AND B = ‘value2’ | Only one NUSI (the one with the stronger selectivity) will be used. |
| 5 | Two separate NUSI, OR combined: {A},{B} | A = ‘value1’ OR B = ‘value2’ | Both NUSI will be used if strong selectivity is given |
| 6 | {A} | LIKE ‘%value%’ | Used if strong selectivity is given( NUSI subtable scan is done, no binary search) |
Example 1:
The Optimizer abstains from utilizing the NUSI for a specific reason, although it may not be apparent initially. It is crucial to recollect how rows are stored in the index sub-table data blocks. In the case of a hash-ordered NUSI, the array of row pointers is arranged according to the row hash value. However, since we only have a constraint on column A, we cannot employ the index hash value of {A, B} to perform a binary search on the index data blocks. As a result, only a full table scan on the index sub-table would be feasible. Nevertheless, the Optimizer never regards this as a viable alternative.
Example 2:
Example 2 is an ideal scenario for utilizing NUSI. When there is a high degree of selectivity, the Optimizer will opt for NUSI. The Row hash of the index corresponds to the row hash of the WHERE condition columns {A, B}, which enables the hash value calculation of the WHERE condition. With this hash value, Teradata can rapidly locate the rows in the index sub-table by executing a binary search on the row pointer array.
Example 3:
Although not as ideal as Example 2, the Optimizer should still evaluate this option. It only calculates hash values based on columns A and B in the WHERE condition, resulting in matching row hash values with the NUSI sub-table.
A binary search on the row pointer array is executed; the remaining qualifier on column C is applied as the residual condition.
Example 4:
At least one NUSI with strong selectivity must be combined with AND when using two or more in the following manner:
The Optimizer selects the NUSI with the highest selectivity from the available NUSIs. However, NUSI Bit mapping is an alternative approach for combining multiple NUSIs with low selectivity. More on this topic will be discussed shortly.
Example 5:
Multiple NUSIs, each requiring high selectivity, can be combined with OR to achieve the desired outcome.
Retrieving ROWIDs from indexes A and B and consolidating them into a shared spool eliminates duplicate ROWIDs, necessitating a spool sort operation. In cases where the index is not comprehensive, the ROWIDs facilitate access to base table rows.
Important notes:
The Optimizer deems the aforementioned sorting procedure as highly expensive. Even with a high level of selectivity, if numerous rows necessitate sorting, the Optimizer may decline the utilization of NUSI.
If you have two WHERE conditions combined with OR and only one of them has a NUSI, the Optimizer will choose a full table scan. This is because the WHERE condition without NUSI already requires an FTS, making it unnecessary to access the available NUSI.
If the Optimizer refuses to use two NUSIs due to the high cost of sorting, we can modify the query to ensure the utilization of both NUSIs.
SELECT * FROM table WHERE colA = 'value1' OR colB = 'value2'can be rewritten to:
SELECT * FROM table WHERE colA = 'value1'
UNION
SELECT * FROM table WHERE colB = 'value2'
If both NUSIs exhibit high selectivity, the optimizer will utilize them. This is because the sorting step has been transferred to the “execution logic” and is no longer considered input for the optimizer’s cost estimation.
Example 6:
A full table scan reads the index row in the index sub-table without utilizing binary search on data blocks. Thus, every block must be checked, resulting in a full table scan. However, the Optimizer may still utilize the index if it anticipates the index sub-table FTS on a smaller table than the base table. It is important to note that only ‘x%’ queries will function as the Optimizer can estimate available statistic histograms on the index column. Queries such as ‘%x%’ will not work as no statistics can be calculated.
The Value Ordered NUSI
Briefly, we discussed value orders. A NUSI ordered by value is particularly beneficial for range scans, such as retrieving rows within a specific date range. Both the master and Cylinder Index hold information on all NUSI data blocks that hold qualifying rows. The AMP can cease the search within a NUSI data block once the searched value moves outside the row pointer array. This is usually accomplished through an FTS on the NUSI subtable within a restricted range of the data blocks.
NUSI Bit mapping
The Optimizer can utilize NUSI bit mapping to consolidate several NUSIs with weak selectivity. As a proprietary algorithm, bit mapping incurs cost overhead, rendering usage less predictable. NUSI bit mapping is solely accessible when more than one WHERE condition is combined with AND. It is employed when multiple NUSIs having weak selectivity can be consolidated, resulting in high selectivity.
For instance, imagine a table with two columns.
The initial column denotes the GENDER, with an equal distribution of 50% men and 50% women. A NUSI focusing on gender may exhibit weak selectivity. The subsequent column is labeled as the “has beard” indicator, presenting two possible values: “yes” or “no.” Presuming that most men possess facial hair in this illustration, a NUSI targeting “has a beard” would likely display weak selectivity.
The Optimizer would not solely rely on NUSI, as FTS would likely be more cost-effective.
A song contest took place recently in Europe, and a bearded woman won it. This is a unique occurrence as such a combination is rare. On consulting our table, we found that both NUSI could be combined for this individual, resulting in high selectivity.
Index Coverage / The Index-Only access
Full or partial coverage under NUSI is feasible. Complete coverage necessitates no access to the base table rows to fulfill the request. If not, the base table rows have to be extracted, and a spool is employed to subsequently access the base table rows. NUSI full coverage is granted if any of the following conditions are met:
- No reference to columns other than those in the NUSI
- NUSI includes all columns in the base table referenced, and upon reference to a character column, it has to be either NOT CASESPECIFIC or UPPERCASE
The conventional method to test a NUSI is:
Create the NUSI you would like to be used and check if it’s indeed used (EXPLAIN statement says something like “by traversing index #1” or “by way of index #1”). If used, keep it; otherwise, drop it (remember, secondary indexes are physical tables occupying disk space).
What is the appropriate Teradata NUSI Workload?
A Unique Secondary Index (USI) allows immediate access to data records, making it suitable for accessing a single customer’s information. Conversely, Non-Unique Secondary Index (NUSI) access is more practical when accessing multiple data rows simultaneously, making it ideal for decision support workloads. However, index maintenance can be substantial in OLTP environments with a heavy load of DML operations.
Teradata Load Utilities and the NUSI
The Fastload utility cannot load into a table with a defined NUSI. To proceed, one must drop the NUSI before loading and recreate it afterward. This limitation is reasonable since Teradata only allows fast loads on empty tables. Unlike Fastload, Multiloads are compatible with NUSI; hence, it is unnecessary to drop it before loading. However, a performance-based approach similar to Fastload’s drop and recreate can be considered.
Learn more about indexing by visiting these links:
– Teradata Indexing
– Choosing a Primary Index

[…] The Teradata NUSI […]
There is no FTS scan required but a scan on a range. This means that not all data blocks have to be moved from the disk to the FSG cache, but only a limited range of blocks. Nevertheless, NUSI access is always an all-AMP operation, as the index rows of the NUSI are co-located with the base table rows. I like to distinguish between the following kind of access types:
(1) all-AMP versus single-AMP or group-AMP
(2) Sequential search versus binary search (within data blocks).
FTS, for example, is always done via a sequential search of all data blocks (or a range of blocks like in our NUSI example above).
We have the following combinations (leaving out partitioning for the moment and examples in brackets):
– All-AMP sequential search (FTS)
– All-AMP binary search (NUSI with hashed access)
– All-AMP, sequential search (NUSI access via FTS on a range of or the complete index subtable)
– Single-AMP (group-AMP) with binary search (indexed lookup: UPI, NUPI, USI)
The Join Index can cover some of the above combinations, depending on if accessed via the primary index or FTS (for example, if the optimizer prefers to an FTS on the smaller join index than on the base table).
I hope these examples answered your question.
Best Regard,
Roland
“By sorting the NUSI rows by data value, it is possible to search only a portion of the index subtable for a given range of key values. The major advantage of a value-ordered NUSI is in the performance of range queries.” – so by this statement, no FTS or no All-AMP access is required, right? please clarify.